1.
papers
❱
1.1.
pollux
1.2.
adasum
1.3.
adaptation_learning
1.4.
gradient_descent
1.5.
auto_parallel
1.6.
scheduling
1.7.
gradient_compression
❱
1.7.1.
dgc
1.7.2.
csc
Light (default)
Rust
Coal
Navy
Ayu
Papers
Scaling distributed training with adaptive summation
Saeed Maleki et al. Microsoft Research
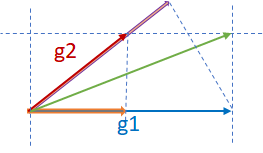
Key point
g
=
(
1
−
2
∣
g
1
∣
2
g
1
⋅
g
2
)
g
1
+
(
1
−
2
∣
g
2
∣
2
g
1
⋅
g
2
)
g
2
Reference
AdaSum with Horovod
Arxiv